Basic to C Translator (b2c)
b2c developed from my earliest gaming interests back in the 1980s when games where written and distributed in listing-format in various flavors of the BASIC programming language.
Back then an old friend of mine, Dave, and I spent many hours laboriously typing in these programs from paper listings of the source code. OCR wasn’t a reality for us yet. Both Dave and I worked on mainframe computers so games were pretty rare. So after many hours of cramped hands we got to play our games. They were trivial but fun.
However, BASIC has gone from an interesting alternative to my commonly used languages of Fortran and Cobol (yuk!), at the time, to a nuisance — especially after getting used to structured modern languages.
The idea of translating these programs into C appealed to me but the process didn’t so I decided to let my university education kick in and I built a Lex/Yacc based translator to convert the source code from Basic to C. It seemed to work really well. The days and weeks it took to develop b2c was well offset by the 1/10sec it took to translate these BASIC programs ;-).
If you are a programmer you’ll understand that the more sophisticated compiler programming was a lot more rewarding than the original games so I lost a little bit of my interest in the games themselves.
The b2c project got to the point where I wanted to convert the BASIC spaghetti code into a structured C instead of doing a straight line-for-line translation. But I got bogged down in trying to translate my parse tree in place and put the project down for a while.
When I tripped across a project called BNFC (Backus-Naur Form Converter) this reignited my interest in b2c as it makes the front end considerably easier to re-write from scratch. Or at least I thought it was going much better but then I recognized that the extra burden of learning BNFC and the limitations that it imposed didn’t offset the tedium of writing YACC grammars. Oh, well!
Currently I’m busy writing a game for Android and when I get finished that I’ll go back and work on these translators some more.
Once I get this working again I’d like to continue doing my Fortran-to-C translator because I’ve got the Empire, Galaxy and Star Trek sources I’d like to translate and get working again too.
The file BasicGames.7z contains some translated sources for some familiar Basic games. The translations may not work, or even be completely translated, but they do show the direction I was headed. The original Basic program is included as part of the listings in the ‘cpp’ (really just C) file. The one external file ‘intrinsics.h’ adds some extra functionality that was part of the Basic language which isn’t available directly in ‘C’.
I was also working on a dump2asc.cpp file that translates from Tokenized Basic to human readable Basic. However, this program isn’t well commented yet and is a bit of a mess so will be added here later. It translates from multiple versions of Tokenized Basic but the number of test programs available to debug it is limited so it isn’t perfectly yet. These are the Tokenized Basic versions it knows about so far:
- gwbp – GW-Basic Protected,
- gwbu – GW-Basic Unprotected,
- basx – Unknown XBasic with first byte 0x42, and
- basy – Unknown YBasic with first byte 0x42.
This file (BasicGamesSource.7z) contains most of the Basic source files that I’ve gathered as well as tokenized versions of some of these files. The tokenized versions of the files might have a slightly modified name to the Basic file and are located in the tokenized subdirectory of the directory containing the Basic file.
My dump2asc (Dump-to-ASCII) program is functioning much better now. It translates a tokenized Basic file to a text version (in ASCII). Recently I added the functionality to convert the file with a variety of tokenizations (GW-Basic isn’t the only version) defined mostly by the Tokenized Basic pages at the FileFormats archive. Also added a function to check a tokenized source file against all the known tokenizations with a single invocation and reporting the number of errors for each. This give the user the ability to figure out the tokenization of a file without checking laboriously against each available tokenization.
I just tripped across a tokenized file (programs/launch.bas in the source archive above) that had 0x1D (float) tokenized real numbers and was able to create, and test the code, to translate these to their correct value in the output source. I’ve also implemented (not tested) code for the 0x1F (double) conversion but I don’t have any tokenized files that include those tokens. Please if anybody has tokenized files that you can supply me with to test my de-tokenization with please pass them on to me at NonAligned.Games@gmail.com and I’ll send back the translated copy. So far I’ve been able to test with:
- TRS-80 Level II BASIC tokenized file, and
- GW-BASIC tokenized file (or BASICA)
The list of tokenizations that my program should handle (pending testing) are:
- amos – [F] AMOS BASIC tokenized file
- apfb – [F] APImagination Machine BASIC tokenized file
- apfi – APF Imagination Machine BASIC tokenized file
- apib – Apple Integer BASIC tokenized file
- apsb – Applesoft BASIC tokenized file
- atar – [F] Atari BASIC tokenized file
- basx – Unknown XBasic with first byte 0x42
- basy – Unknown YBasic with first byte 0x42
- bbcb – [F] BBC BASIC tokenized file
- cceb – [F] CCE MC-1000 BASIC tokenized file
- cole – Coleco ADAM SmartBASIC tokenized file
- comm – Commodore BASIC tokenized file
- comp – Compucolor BASIC tokenized file
- exid – Exidy Sorcerer BASIC tokenized file
- gwba – GW-BASIC tokenized file (or BASICA)
- gwbp – GW-BASIC tokenized file (or BASICA) protected
- gwbu – [F] GW-BASIC tokenized file (or BASICA) unprotected
- matt – [F] Mattel Aquarius BASIC tokenized file
- mbas – MBASIC tokenized file (Microsoft BASIC for CP/M)
- nasc – NASCOM BASIC tokenized file
- ohio – Ohio Scientific BASIC tokenized file
- sinc – [F] Sinclair BASIC tokenized file (for ZX80, ZX81 and Spectrum)
- solb – Sol BASIC tokenized file
- sole – Sol BASIC tokenized file
- tiba – TI BASIC tokenized file (TI 99/4A)
- tibe – TI BASIC tokenized file (TI 99/4A)
- tiny – [F] Tiny BASIC tokenized file (ran on KIM-1 and some other early machines)
- trs2 – TRS-80 Level II BASIC tokenized file
- trsc – TRS-80 Color BASIC tokenized file
The [F] indicates a tokenization to be implemented in the future. The gwbp, gwbu, basx, and basy were tokenizations I developed before I became aware of the FileFormats archive.
On another note, I’ve returned to working on my b2c (translates Basic, all flavours, to C) program. I’m a little horrified by some of my design decisions way back then so I’ll be revisiting those. I have been able to get some translated C programs running. The larger programs like Super Star Trek are still causing problems but that will just be a process of debugging all the translation nuances. I’ll start posting some of the translations as they become available.
Some useful links to {Super} Star Trek:
- Star Trek (1971 video game) (Wikipedia)
- List of Star Trek games (Wikipedia)
- Tom Almy’s version
- BSD Trek (Github. This appears to be a subset of Tom Almy’s version)
May 03,2022
Managed to get b2c to translate strek2.bas fairly successfully. The C-file compiles and the resulting program runs but has bugs. The compile command is:
g++ -std=c++11 -g -Wno-write-strings strek2.c -o strek2
The 7zip-archive strek2.z7 has five files:
- intrinsics.h – The header file that includes all the support routines to implement things like MID$(<str>,<start>,<length>) and other Basic functions.
- strek2.bas – The original Basic file.
- strek2.c – The translated C file.
- strek2.log – The log file from the translation of the Basic program.
- strek2.vars – The translation from the mangled variable/function/label names to user-chosen names.






Hi,
I need to translate some old unstructured BASIC code into C or any other currently used language.
Can you share your B2CTrans project?
Thanks in advance
Hi Basilio,
Sorry, to take so long to respond…
Unfortunately, I put the b2ctrans project in limbo for a while so I could work on other projects. I actually started building the translator because I had a number of Basic programs I wanted to convert, including some from an old book “Basic Computer Games” http://www.vintage-basic.net/games.html
As I remember it was doing quite well translating them statement-to-statement (one Basic statement to one C statement(roughly)). However, I wanted to convert Basic programs into structured C which is where I got bogged down.
I’m not sure about the state of the project right now so can’t offer you much.
What type of programs and what flavour of Basic were you wanting to translate? B2Ctrans does some varieties micro basic.
Take care,
/Alan
Hello,
I was wondering how were you able to convert vintage basic to c, specifically with goto and gosub statements? I am currently trying to translate the Star trek game from the “BASIC Computer Games.”
Thanks!
Hi Jay,
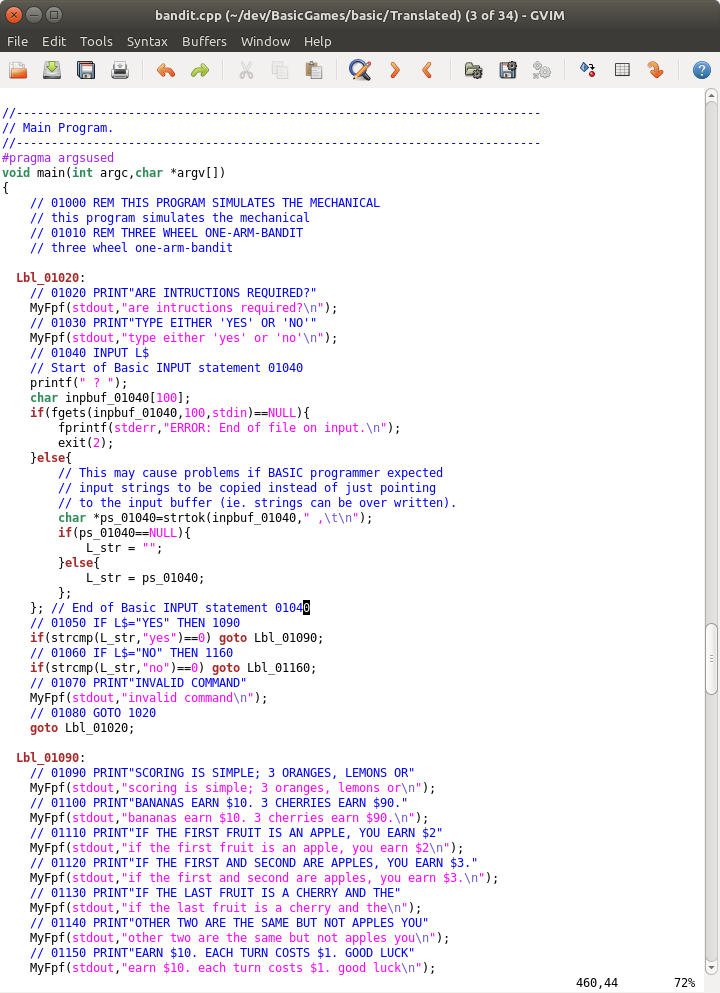
The C language has statements that are almost identical to the Basic statements. For instance for the Basic “GOTO NNNN \n…\n NNNN” has an equivalent in C “goto Lbl_NNNN \n…\nLbl_NNNN: ” so you just have to prefix your Basic line numbers (the ones that are used for GOTO or GOSUB targets) with “Lbl_” or something similar. You can see this in some of the images of listings above.
A Basic GOSUB is just a call to a subroutine. So the Basic “GOSUB NNNN \n…\n NNNN \n…\n END” can be replaced in C with “routine_NNNN \n…\n void routine_NNNN(){ \n … \n }”. But beware Basic subroutines can have multiple entry points. For instance “NNNN … MMMM … END” where the NNNN and MMMM are line numbers and the “\n” represents newlines. My first attempt at this problem just copies the MMMM chunk of code to a completely separate routine. This will duplicate a number of lines of code but it was easy to implement. The hard part in this case is to determine where overlapping subroutines occur.
This was one advantage of b2c because it hunts down all the “active” line numbers (ones used by GOTOs, GOSUBs etc) and traces the flow of control in cases where you have overlapping subroutines (which seems to happen quite often).
The b2c program is written in C++ and uses Flex/Bison to parse the old Basic program which produces an AST (Abstract Syntax Tree) in memory and then runs through the AST to output the equivalent C statements.
BTW, there are a bunch of StarTrek games that seem to have been spawned from, or in parallel with, this initial version.
Take care,
/Alan
Thank you for relating your background and experience with this problem.
I hope that this comment isn’t too late (other comments are around 18 months to 2 years ago).
I had visions (long long ago) of doing similar, but was wanting to convert to C to run (easily/sensibly) on Linux.
(I note from your screen shot that you are a Linux user as well)
The input being, programs written in the GWbasic dialect for DOS, mostly games BUT……
The “Spaghetti code” problem was partly solved when MS brought out QuickBasic which had a utility which omitted unused line numbers.
However converting Basic statements like “pos” or “csrlin” and “line (x y) – (x y)” … etc,
requires the likes of ncurses and sdl (or other graphic screen).
I tried a “basic to C converter” many years ago, but was aghast when it turned a 2k program into over 20k of obtuse code.
I wanted C code which was easy to read and could be compared against its “basic code” counterpart.
My approach has been to convert in steps (mainly for debugging)
– clean out the unused line numbers; get a list of all variables; get a list of all basic statements used
– decide on variable/s data type; substitute hand-written C functions for complicated Statements;
– automatically write a header file, include needed C libraries and global variables
– determine unused and/or unset variables (I couldn’t get a simple 25 liner to run because “loops” wasn’t init’ed to 0 )
– refactor to get/separate out functions (still just a dream)
Like you, I keep coming back to my translator…
esp. When I find an old Basic game that would be nice to have working in C to run on Linux
and … to maybe also have a coding language to allow quick prototyping
Hi John,
I actually started working on this problem as a interesting diversion a long time ago — it appears one of the listings has a Windows file structure. I abandoned Windows eons ago when I found out all the filters I had to write on Windows where already in linux as standard (and much better than my programs).
It probably would have been easier to re-write the basic code by hand but I wanted to try using Flex/Bison as my lexical-analyser and parser generators. Those seemed to work fairly well.
But while playing with that code I noticed that some of the code had ‘subroutines’ with multiple entry&exit points so I first unraveled that code.
After that I was working on trying to induce some structure into the code (for/while loops etc) so I didn’t have to use GOTOs and labels. For some reason I tried to do translation in-place instead of coding from one statement* vector to another (kinda a crazy decision with a little hindsight).
That’s probably when some shiny piece of code caught my eye and I got distracted. I do intend to get back to it sometime … I’m busy working on my Royals game right now so it will be a while.
If you look at the picture of the listings I put up the program intersperses Basic and C lines so it is easy to see what C code is being generated for each Basic line. There is some ancillary code like MyFpf() function which is just a shell around a vfprintf(). My approach is very much like yours.
Keep in touch … I’m curious how your project is going. I’ll try and put up some of the listings I’ve generated so you can see my translations in more detail.
Take care,
/Alan
I went from DOS to Linux about the time Windows 3.1/XP came out
(probably hung on to DOS for too long, but I had a CAD and other that used DOS)
That is when I wanted to migrate most of my DOS/gwBasic programs to Linux
Initially I did a C program that emulated the QBasic utility that omitted unused line numbers.
(my reasoning was to not rely on anything MS and/or was a locked black box)
I looked at flex/Bison but it seemed an unnecessary/complicating step which still eventually needed a hand written function to substitute for the Basic statement (and at that stage I was still undecided on which graphic window)
I decided to suffer GOTO’s (as C had these) to get a working C program. And eventually re-structure (if necessary) esp. if/when a good refactoring program for C came along. Also with my approach one gets a terminal window AND a graphic window. Having BOTH these windows allows more than re-structuring, but re-jigging/evolving the program.
My converter/translator also echoes the original Basic Program Line (before its C line/s) as a comment
This is switchable on/off (via option/s on the Command Line).
I am also looking at echoing the original to the right after the C line (like bcx does )
Because I did it in steps, the total conversion is done via a shell script executing each step in turn
Would you like an example, ie. the generated C code for a simple gwBasic program? How do I get it to you?